scutr: SMOTE and Cluster-Based Undersampling Technique in RImbalanced training datasets impede many popular classifiers. To balance training data, a combination of oversampling minority classes and undersampling majority classes is necessary. This package implements the SCUT (SMOTE and Cluster-based Undersampling Technique) algorithm, which uses model-based clustering and synthetic oversampling to balance multiclass training datasets.
This implementation only works on numeric training data and works best when there are more than two classes. For binary classification problems, other packages may be better suited.
The original SCUT paper uses SMOTE (essentially linear interpolation between points) for oversampling and expectation maximization clustering, which fits a mixture of Gaussian distributions to the data. These are the default methods in scutr, but random oversampling as well as some distance-based undersampling techniques are available.
You can install the released version of scutr from CRAN with:
And the development version from GitHub with:
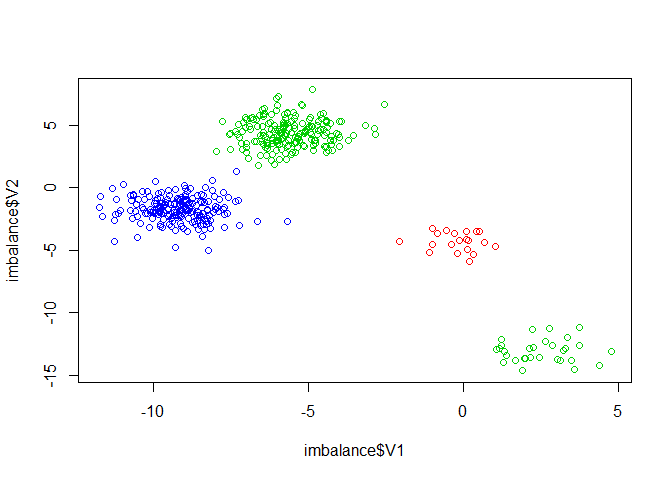
We start with an imbalanced dataset that comes with the package.
library(scutr)
data(imbalance)
imbalance <- imbalance[imbalance$class %in% c(2, 3, 19, 20), ]
imbalance$class <- as.numeric(imbalance$class)
plot(imbalance$V1, imbalance$V2, col=imbalance$class)
Then, we apply SCUT with SMOTE oversampling and k-means clustering with seven clusters.
scutted <- SCUT(imbalance, "class", undersample = undersample_kmeans,
usamp_opts = list(k=7))
plot(scutted$V1, scutted$V2, col=scutted$class)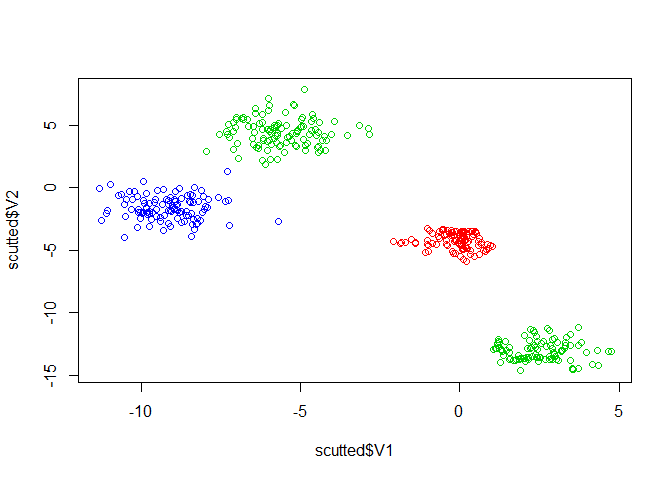
The dataset is now balanced and we have retained the distribution of the data.